Second node fails to start due to read timed out accessing dbo.clusteredjob with MS SQL Server database
Platform Notice: Data Center Only - This article only applies to Atlassian apps on the Data Center platform.
Note that this KB was created for the Data Center version of the product. Data Center KBs for non-Data-Center-specific features may also work for Server versions of the product, however they have not been tested. Support for Server* products ended on February 15th 2024. If you are running a Server product, you can visit the Atlassian Server end of support announcement to review your migration options.
*Except Fisheye and Crucible
Summary
Starting a second node fails with Read Timed Out Exception while executing the following SQL command:
DELETE FROM dbo.clusteredjob WHERE JOB_ID=? (Read timed out)When only one node is running, the node works fine.
2020-11-26 10:17:18,652-0500 localhost-startStop-1 ERROR [c.a.j.component.pico.ComponentManager] Error occurred while starting component 'com.atlassian.jira.web.action.issue.DefaultTemporaryWebAttachmentsMonitor'.
com.atlassian.jira.exception.DataAccessException: org.ofbiz.core.entity.GenericDataSourceException: Generic Entity Exception occurred in deleteByAnd (SQL Exception while executing the following:DELETE FROM dbo.clusteredjob WHERE JOB_ID=? (Read timed out))
at com.atlassian.jira.ofbiz.DefaultOfBizDelegator.removeByAnd(DefaultOfBizDelegator.java:238)Diagnosis
1) Database shows sleeping process and multiple suspended requests:
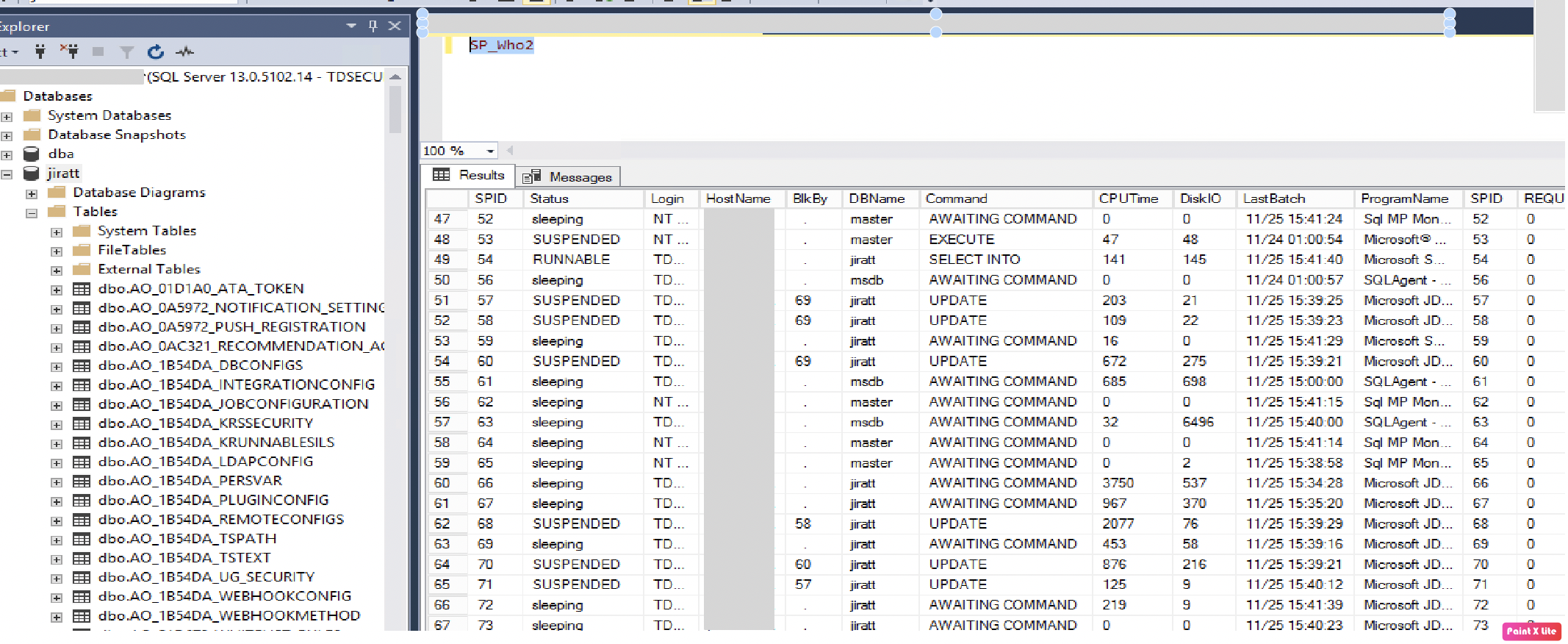
Some of them are related to the table dbo.clusteredjob:
(@P0 bigint,@P1 bigint,@P2 nvarchar(4000),@P3 bigint)UPDATE dbo.clusteredjob SET VERSION = @P0 , NEXT_RUN = @P1 WHERE JOB_ID=@P2 AND VERSION=@P3 (suspended)
(@P0 bigint,@P1 bigint,@P2 nvarchar(4000),@P3 bigint)UPDATE dbo.clusteredjob SET VERSION = @P0 , NEXT_RUN = @P1 WHERE JOB_ID=@P2 AND VERSION=@P3 (suspended)
(@P0 bigint,@P1 bigint,@P2 nvarchar(4000),@P3 bigint)UPDATE dbo.clusteredjob SET VERSION = @P0 , NEXT_RUN = @P1 WHERE JOB_ID=@P2 AND VERSION=@P3 (suspended)
(@P0 nvarchar(4000))DELETE FROM dbo.clusteredjob WHERE JOB_ID=@P0 (sleeping)2) Log files on both nodes (the already started one and the second failed node) shows multiple Read Timed Outs as the sample below:
2020-11-25 20:20:09,383-0500 Caesium-1-3 ServiceRunner 300151ms "UPDATE dbo.clusteredjob SET VERSION = '11' , NEXT_RUN = '1606353369231' WHERE JOB_ID='com.atlassian.jira.plugin.ext.bamboo.service.PlanStatusUpdateJob-job' AND VERSION='10'"
com.microsoft.sqlserver.jdbc.SQLServerException: Read timed out
at com.microsoft.sqlserver.jdbc.SQLServerConnection.terminate(SQLServerConnection.java:2887) [mssql-jdbc-7.2.1.jre8.jar:?]
[...]
Caused by: java.net.SocketTimeoutException: Read timed out
at java.net.SocketInputStream.socketRead0(Native Method) [?:1.8.0_265]Environment
Jira DC
Microsoft SQL Server 2016
Cause
Commit was not being executed at the Database.
Solution
1) Make sure the JDBC connection is not using autocommit=false. If it is using, remove it.
Sample for SQL Server:
jdbc:sqlserver://SQLHostname:3341;databaseName=jira;domain=TDBFG;IntegratedSecurity=true;UseNTLMv2=true;AuthenticationScheme=JavaKerberos;autoCommit=false;socketTimeout=3000002) Ensure the database is set toREAD_COMMITTED_SNAPSHOT ONas perConnecting JIRA to SQL Server.
To verify the changes, use this query which should result in '1':
SELECT sd.is_read_committed_snapshot_on
FROM sys.databases AS sd
WHERE sd.[name] = '<database name>';Was this helpful?