Duplicate Jira tickets are created from the same incoming email due to indexing errors
Platform Notice: Data Center Only - This article only applies to Atlassian apps on the Data Center platform.
Note that this KB was created for the Data Center version of the product. Data Center KBs for non-Data-Center-specific features may also work for Server versions of the product, however they have not been tested. Support for Server* products ended on February 15th 2024. If you are running a Server product, you can visit the Atlassian Server end of support announcement to review your migration options.
*Except Fisheye and Crucible
Summary
This article describes a scenario where the Jira Mail Handler (configured in ⚙ > System > Incoming Mail) might create duplicate issues from the same incoming email, how to identify this scenario, and how to fix the issue.
⚠️ Note that this KB article should not be confused with the other KB article Duplicate Jira tickets are created from the same incoming email due to incorrect default time stamp, which addresses a different situation where duplicate tickets might be created from the same incoming email. If you do not find in the Jira logs the error mentioned in this KB article, then please refer to other KB article and check if you can find the error from that one.
Environment
Jira Data Center on any version from 8.0.0, with a cluster of at least 2 nodes.
Jira is configured with a Mail Handler configured ⚙ > System > Incoming Mail to fetch incoming emails from a mail server and create new issues from them
Diagnosis
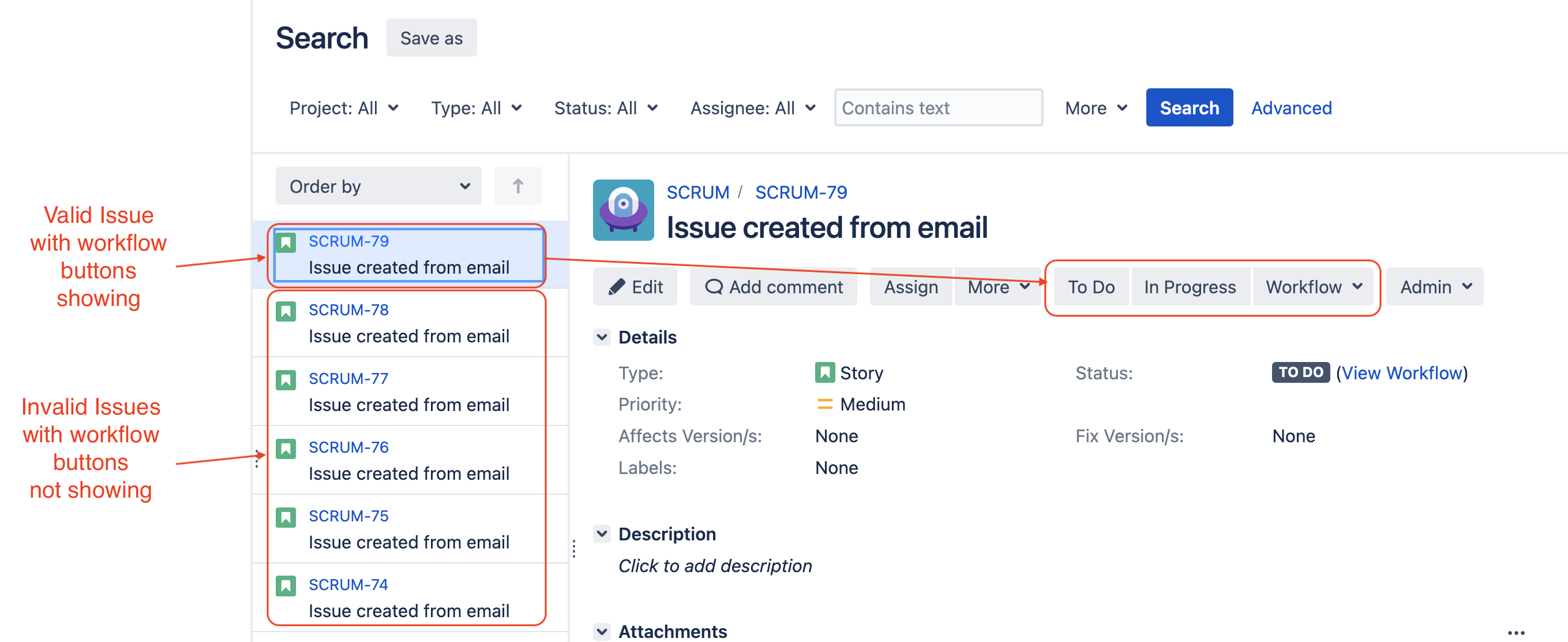
Check the Jira issues that were created during a short period of time, with the exact same summary (which corresponds to the subject of the same incoming email). If you make the observation below, then this KB article might be relevant:
The most recent issue is in a valid state, meaning that the workflow buttons are showing as expected
The duplicate issues created before are in invalid state, meaning that no workflow buttons are showing in the Issue View screen
Check the Jira Incoming Mail Logs from both nodes:
On a non healthy node (for example Node 2), you should see that the same incoming email was processed multiple times by the same mail handler, but failed due to an indexing error
1st attempt at 13:18pm
2023-03-15 13:18:02,113+0100 DEBUG [Incoming Mail Server] Caesium-1-3 anonymous Mail Handler No Issue found for email 'Issue created form email' - creating a new Issue. ... 2023-03-15 13:18:02,113+0100 DEBUG [Incoming Mail Server] Caesium-1-3 anonymous Mail Handler CreateIssueHandler.handleMessage ... 2023-03-15 13:18:02,656+0100 WARN [Incoming Mail Server] Caesium-1-3 anonymous Mail Handler Mail Handler[11700]: Unable to create issue with message. com.atlassian.jira.exception.CreateException: com.atlassian.jira.workflow.WorkflowException: Indexing completed with 1 errors at com.atlassian.jira.issue.managers.DefaultIssueManager.createIssue(DefaultIssueManager.java:508) [classes/:?] at com.atlassian.jira.issue.managers.DefaultIssueManager.createIssueObject(DefaultIssueManager.java:602) [classes/:?] at com.atlassian.jira.issue.managers.RequestCachingIssueManager.createIssueObject(RequestCachingIssueManager.java:212) [classes/:?] at com.atlassian.jira.service.util.handler.DefaultMessageHandlerContext.createIssueWithIssueManager(DefaultMessageHandlerContext.java:248) [jira-api-8.20.14.jar:?] at com.atlassian.jira.service.util.handler.DefaultMessageHandlerContext.createIssue(DefaultMessageHandlerContext.java:166) [jira-api-8.20.14.jar:?] ...2nd attempt at 13:19pm
2023-03-15 13:19:02,179+0100 DEBUG [Incoming Mail Server] Caesium-1-2 anonymous Mail Handler No Issue found for email 'Issue created form email' - creating a new Issue. ... 2023-03-15 13:19:02,179+0100 DEBUG [Incoming Mail Server] Caesium-1-2 anonymous Mail Handler CreateIssueHandler.handleMessage ... 2023-03-15 13:19:02,712+0100 WARN [Incoming Mail Server] Caesium-1-2 anonymous Mail Handler Mail Handler[11700]: Unable to create issue with message. com.atlassian.jira.exception.CreateException: com.atlassian.jira.workflow.WorkflowException: Indexing completed with 1 errors at com.atlassian.jira.issue.managers.DefaultIssueManager.createIssue(DefaultIssueManager.java:508) [classes/:?] at com.atlassian.jira.issue.managers.DefaultIssueManager.createIssueObject(DefaultIssueManager.java:602) [classes/:?] at com.atlassian.jira.issue.managers.RequestCachingIssueManager.createIssueObject(RequestCachingIssueManager.java:212) [classes/:?] at com.atlassian.jira.service.util.handler.DefaultMessageHandlerContext.createIssueWithIssueManager(DefaultMessageHandlerContext.java:248) [jira-api-8.20.14.jar:?] at com.atlassian.jira.service.util.handler.DefaultMessageHandlerContext.createIssue(DefaultMessageHandlerContext.java:166) [jira-api-8.20.14.jar:?] ...
On a healthy node (for example Node 1), you should see that the Mail Handler managed to process the incoming email without any error (after the other node kept failing)
2023-03-15 13:20:02,101+0100 DEBUG [Incoming Mail Server] Caesium-1-2 anonymous Mail Handler No Issue found for email 'Issue created form email' - creating a new Issue. ... 2023-03-15 13:20:03,085+0100 DEBUG [Incoming Mail Server] Caesium-1-2 anonymous Mail Handler CreateIssueHandler.handleMessage ... 2023-03-15 13:20:05,290+0100 INFO [Incoming Mail Server] Caesium-1-2 anonymous Mail Handler Mail Handler[11700]: Issue SCRUM-79 createdCheck the Jira logs from the non healthy node (Node 2 in this example), and check if you can find the following indexing folder lock error. If you find it, then this KB article is relevant and you can move on to the Solution section:
2023-03-15 13:30:14,671+0100 NodeReindexServiceThread:thread-0 ERROR [c.a.j.index.ha.DefaultNodeReindexService] [INDEX-REPLAY] Failed re-attempting to replicate index operations for (FailedReplicatedIndexOperation{tries=4, maxRetries=4, attemptTime=2023-03-15T13:30:09.560835, operationsCount=1}) com.atlassian.jira.issue.index.SearchUnavailableException: com.atlassian.jira.util.RuntimeIOException: org.apache.lucene.store.LockObtainFailedException: Lock held by this virtual machine: /mnt/efs/atlassian/application-data/jira_node_2/jira/caches/indexesV1/issues/write.lock at com.atlassian.jira.issue.index.ThreadLocalSearcherCache$Cache.retrieveEntitySearcher(ThreadLocalSearcherCache.java:139) at com.atlassian.jira.issue.index.ThreadLocalSearcherCache.getSearcher(ThreadLocalSearcherCache.java:40) at com.atlassian.jira.issue.index.DefaultIndexManager.getEntitySearcher(DefaultIndexManager.java:1019) at com.atlassian.jira.issue.index.DefaultIndexManager.getIssueSearcher(DefaultIndexManager.java:995) at jdk.internal.reflect.GeneratedMethodAccessor838.invoke(Unknown Source)
Cause
The reason why duplicate issues are created by the Mail Handler from the same incoming email is due to various factors:
Jira is on a cluster of multiple nodes
One of the Jira node is "unhealthy", meaning that there is a write lock that is held on the indexing folder, preventing this node from being able to index any issue, ultimately preventing this node from successfully creating new issues (since new issues need to be indexed to be properly created)
Because of this lock that happens on a non healthy node, depending on which Node is ececuting the Jira Mail Handler, the following will happen:
if the mail handler is executed on the healthy Node, an valid issue will be created from the same incoming email
if the mail handler is executed on the non-healthy Node, an invalid duplicate issue will be created from the same incoming email
The exact reason why the lock occurred on the non-healthy node in the first place is unclear, but it might be caused by the bug JRASERVER-74514 - Jira will experience index replication issue when the write.lock file could not be acquired.
Solution
Restart the affected node to clear the lock.
Was this helpful?