Accidental changes to Story Points estimates cause spikes in the Agile Reports
Platform Notice: Data Center Only - This article only applies to Atlassian apps on the Data Center platform.
Note that this KB was created for the Data Center version of the product. Data Center KBs for non-Data-Center-specific features may also work for Server versions of the product, however they have not been tested. Support for Server* products ended on February 15th 2024. If you are running a Server product, you can visit the Atlassian Server end of support announcement to review your migration options.
*Except Fisheye and Crucible
Symptoms
A mistyped story point of an Issue during a Sprint is causing a spike in the Burnup Chart. It may also happen to different reports, like the Burndown chart. Attempting to correct it by changing the Story Points back to what it was actually messed up even more with the report. See the screenshots for example:
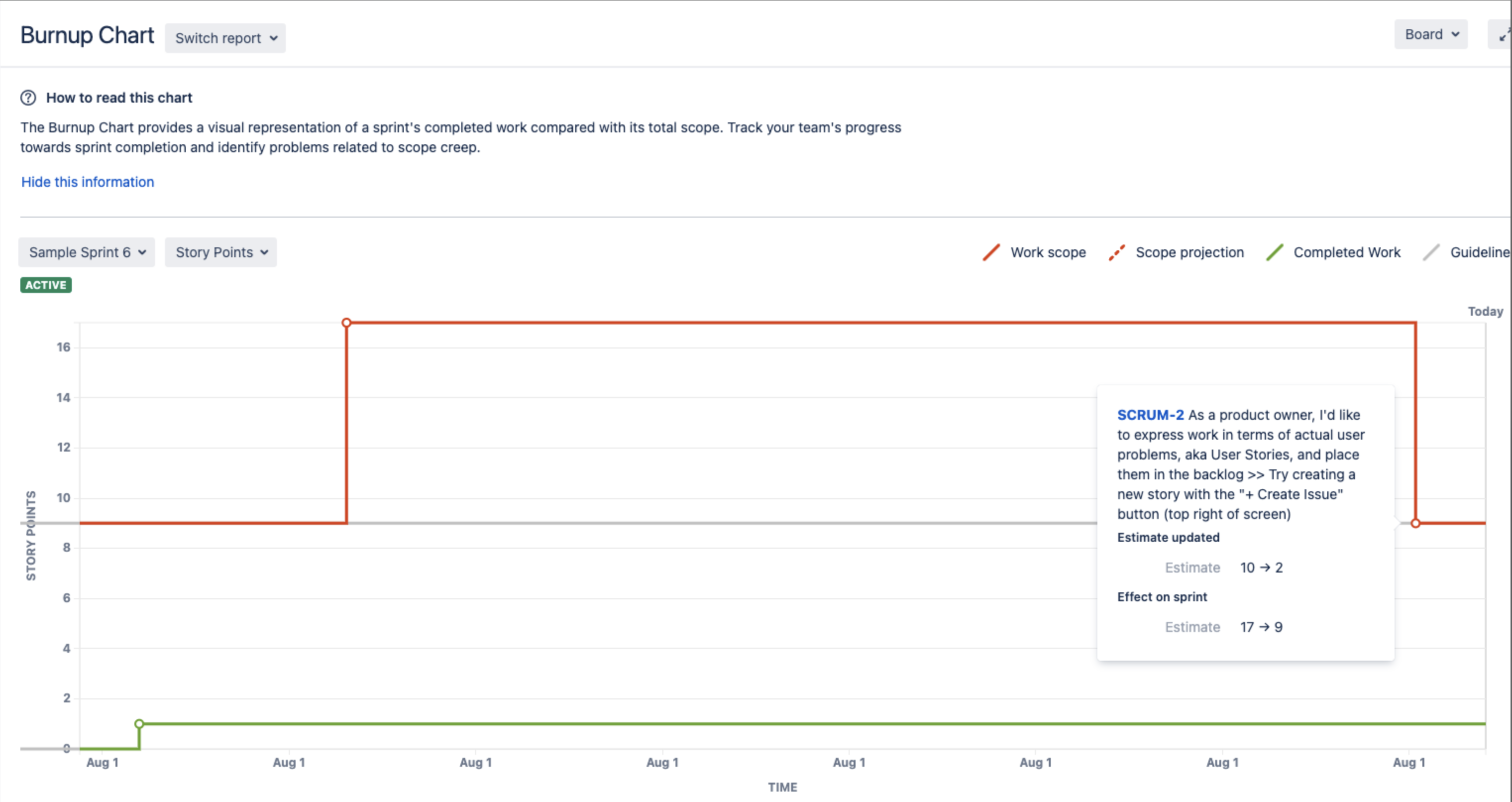
Cause
An Issue estimation input was incorrect. After updating the Estimate the Burnup Chart will still spike as it is a representation of the historical changes.
Workaround
There are two possible workarounds in this case:
Workaround 1
The safest way to work around this scenario would be:
Create a new Sprint.
Add/Move all of your issues to this new Sprint.
Then backdate the Start Date to your original timeframe.
Workaround 2
This one is a little trick, and should only be used in case Workaround 1 is not feasible at all, as this requires database manipulation, which can easily lead to data integrity problems. Additionally, this will require shutting down Jira.
The following steps were tested in a Jira Data Center 9.4.6 with a single node connected to a PostgreSQL and worked fine. However, before doing any changes to your production environment, please make sure to test it in a lower instance first, and even after that, make sure to take a good backup of your production database.
Stop Jira (all nodes, in case you have more than one)
Find the Project ID (replace the 'Project Name' with the correct one)
SELECT id, pname FROM project WHERE pname = 'Project Name';Find the records in the changegroup table (replace the 'ProjID' with the ID found in the previous query, and the 'IssueNum' with the number from the Issue Key in question)
select JI.project, CG.ID as "Change Group", CI.ID as "Change Item", FIELD, OLDVALUE, OLDSTRING, NEWVALUE, NEWSTRING from changegroup CG left join changeitem CI on CG.id = CI.groupid left join jiraissue JI on CG.issueid = JI.ID where JI.issuenum = 'IssueNum' and JI.project = 'ProjID' and FIELD = 'Story Points' order by CG.CREATED asc;You should get something similar to the following:
Examine the results carefully and take note of the values from the "Change Group" that is wrong - in the example above, it was the 11100 and 11102
Run the following DELETE statements to remove the desired lines (replace the 11100 and 11102 with the values you found in the previous query):
delete from changeitem where groupid in (11100,11102); delete from changegroup where id in (11100,11102);Start Jira
ℹ️ In case you have more than one node: start just one first and validate the results. If all is fine, then proceed with starting the remaining nodes.

Was this helpful?