Add missing column after “Pivot” step
Platform Notice: Cloud Only - This article only applies to Atlassian apps on the cloud platform.
Let’s say you have three distinct values in a column, but your result set doesn’t have a row for one of those values. When you use a "Pivot" step on that column, the missing value won’t become a new column in your transformed result set. If you want this value to still be present, even though there are no rows for that value in your current result set, here’s how you can add that missing column.
For our example, we’ll use our Atlassian Data Lake data source. We want to get how many issues are created per each issue status category type are created over a specified number of days; that number is pulled from a "Text input" control. We know there are three distinct values in our Status Category column: To Do, In Progress, and Done. However, depending on our filter, there may not be data for one or some of those document types for the given time period. In our example, there are no rows related to the “Done” status category type when we query data over the past two days, so when we pivot that column in a Visual SQL step, there isn’t a column for “Done”!
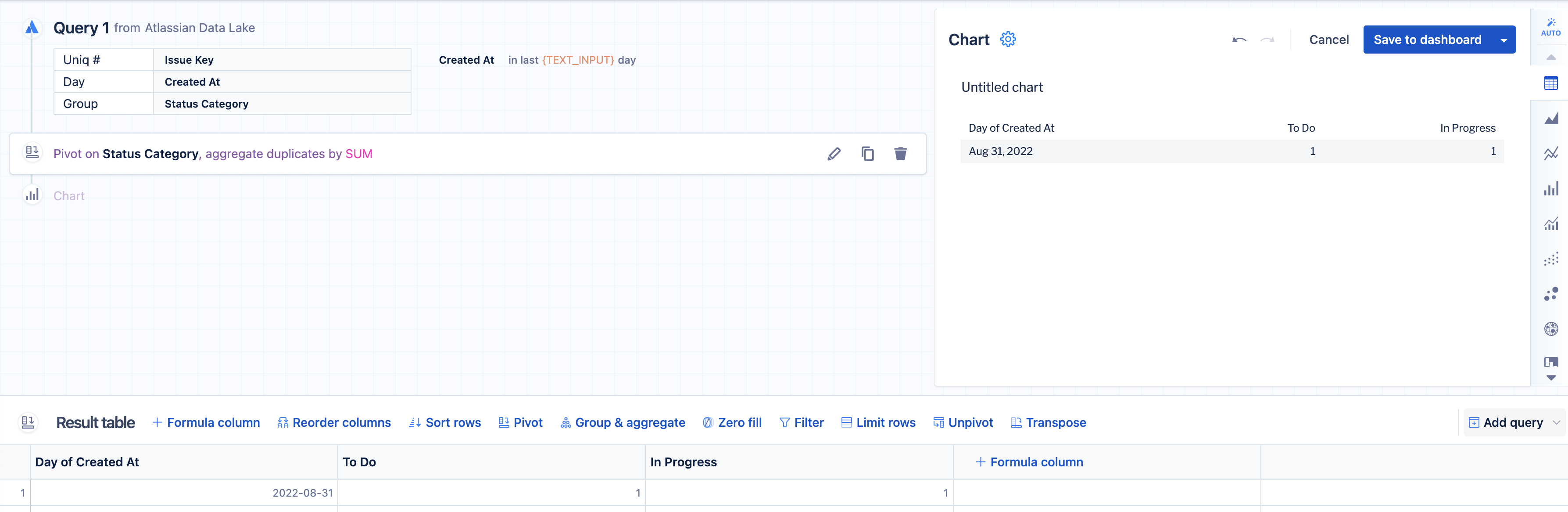
To solve this, we need to broaden our time range so all the distinct values are available in our initial query. For this example, we get at least one row for each document type value when we look at the last 45 days rather than just two days.
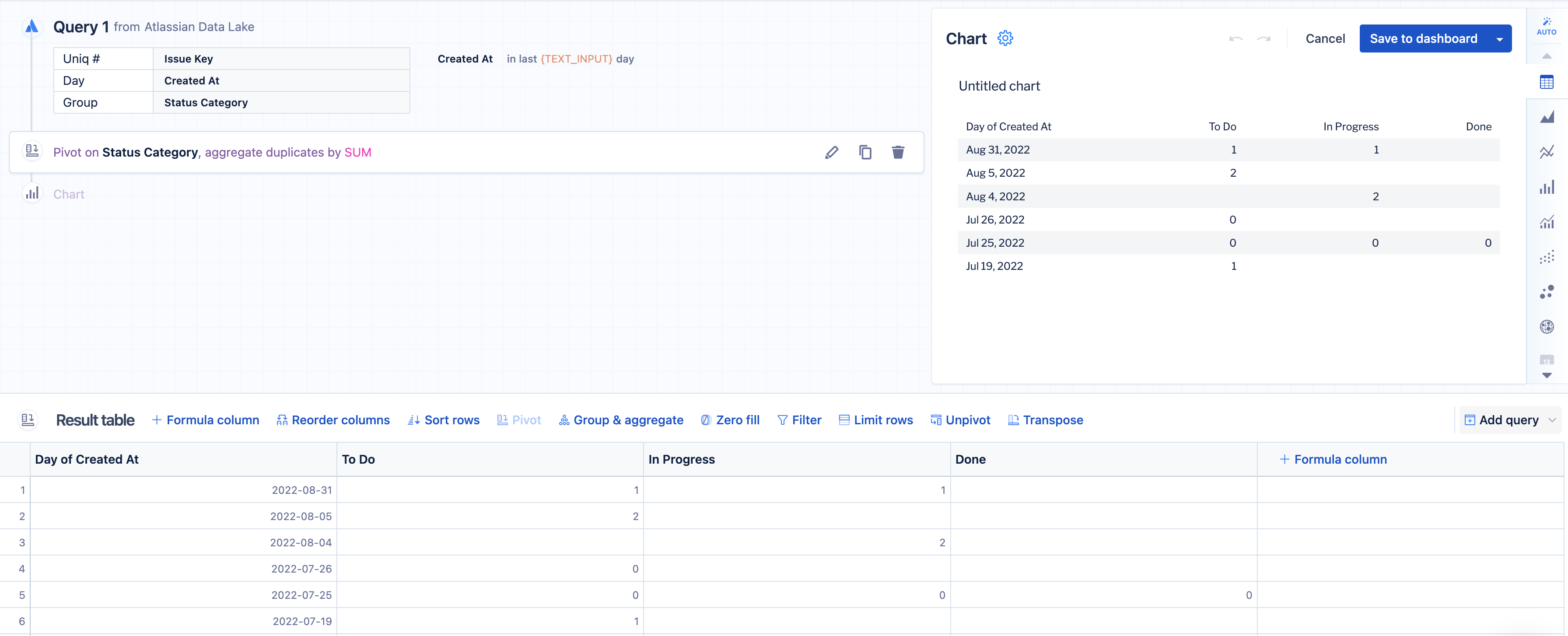
After the pivot, we’ll do the following for each distinct value we know is in our column:
1. Create a new column using a "Formula column" step using the following custom formula, replacing column_name with the value:
"column_name" = NULL2. Rename the new column so it has the same name as the original.
Here’s how it looks when we do this for our example:
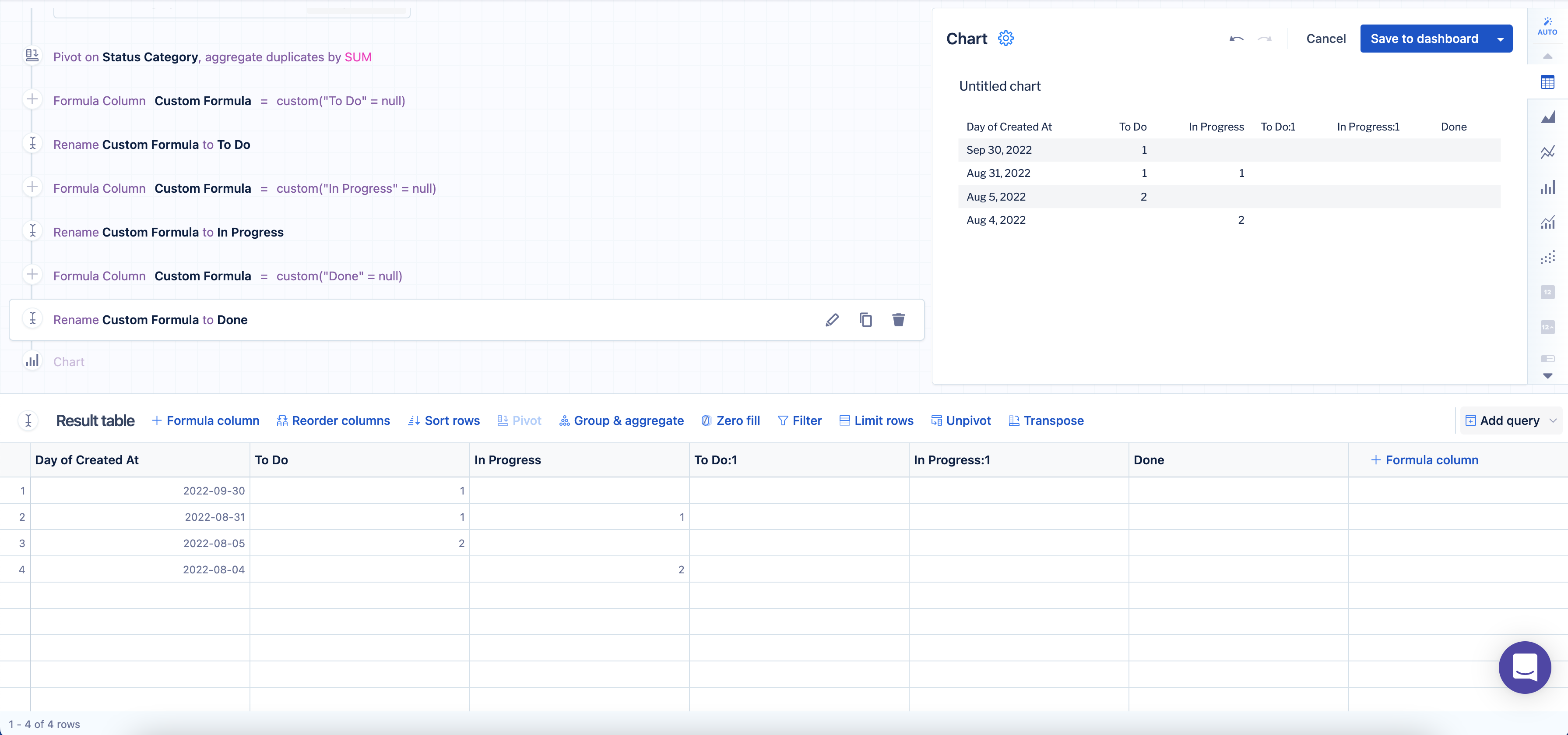
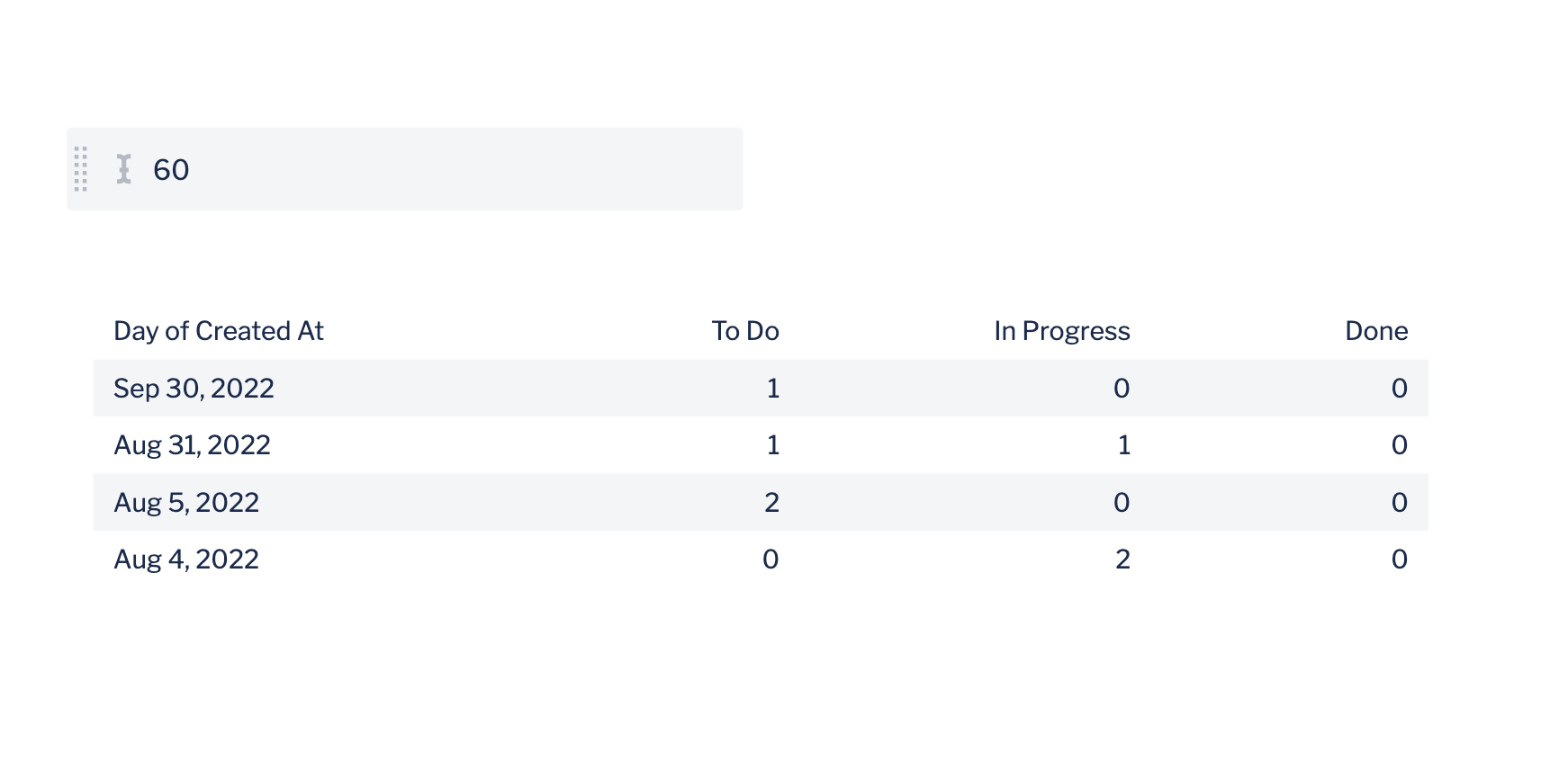
3. If the column name already exists, Visual SQL appends :1to the name of the new column with the same name to distinguish between the new and the original. This is why we use the same column names for our new columns—so we can identify if the column existed already or not. Now we can hide any columns with :1appended to it, which would be all of them except the Done column.

Now all of our statuses are visible in the final table chart!
Was this helpful?